Django REST framework Serializers 내부 동작 파악하기 😎
strongly restrict the ordering of operations/properties
안녕하세요. 페이히어 Enterprise squad에서 백엔드 개발을 하고 있는 장지창입니다. 😎
페이히어 백엔드 개발팀은 Python, Go, Kotlin을 포함한 다양한 언어와 Django, FastAPI, Gin, Spring을 포함한 다양한 프레임워크로 서비스를 만들고 있습니다.
저는 페이히어 서버 중 큰 비중을 차지하는 Django를 활용해 개발하고 있습니다. 코드 리뷰를 하던 중 Django REST framework(이하 DRF)의 Serializer에 궁금한 점이 생겼습니다. 그래서 DRF의 내부 코드를 파악하고 동작 순서를 정리하여 팀원들과 공유하는 시간을 가졌습니다. DRF를 사용하고 계신 개발자분이라면, 이 글이 도움 되시길 바라며 글을 시작하겠습니다.
Serializer란?
컴퓨터 과학에서 Serializer는 data structure 또는 object 상태를 저장하거나 전송할 수 있는 형식으로 변환하는 과정을 말합니다. 한국어로 번역하면 직렬화라고 하고, serializer 또는 marshalling이라고 부르기도 합니다.
Serializer in DRF
serializer를 사용하면 쿼리셋 및 모델 인스턴스와 같은 복잡한 데이터를 Python 데이터 타입으로 변환한 다음 JSON, XML 또는 다른 콘텐츠 유형으로 쉽게 렌더링할 수 있습니다.
먼저 serializer를 사용한 예시를 보겠습니다. 아래와 같이 Comment class를 만들고 comment 인스턴스를 만듭니다.
from datetime import datetime
class Comment:
def __init__(self, email, content, created=None):
self.email = email
self.content = content
self.created = created or datetime.now()
comment = Comment(email='leila@example.com', content='foo bar')serializer를 만듭니다.
from rest_framework import serializers
class CommentSerializer(serializers.Serializer):
email = serializers.EmailField()
content = serializers.CharField(max_length=200)
created = serializers.DateTimeField()다음과 같이 serializer 클래스를 사용해 인스턴스를 직렬화합니다.
serializer = CommentSerializer(comment)
serializer.data
# {'email': 'leila@example.com', 'content': 'foo bar', 'created': '2016-01-27T15:17:10.375877'}😄 Serializer 올바르게 사용하기
코드 리뷰에서 생긴 의문
페이히어 개발팀은 개발자가 작성한 코드를 개인의 소유가 아니라 공동의 소유로 생각합니다. 따라서 코드의 실수로 인해서 장애가 발생했을 때, 해당 코드를 작성한 사람을 비난하는 것이 아니라 시스템의 문제를 파악하고, 그것을 고쳐 나갑니다. 아래처럼 코드를 작성하고 PR을 생성했습니다.
class GroupAPIView(GenericAPIView):
read_serializer_class = GroupReadSerializer
def get(self, request: Request):
...
serializer = self.get_read_serializer(data=group)
if not serializer.is_valid(raise_exception=False):
raise ValidationError(MetaType.parse_error)
return Response(serializer.data)
이에 대해 팀원들이 코멘트를 남겼습니다. 🤩
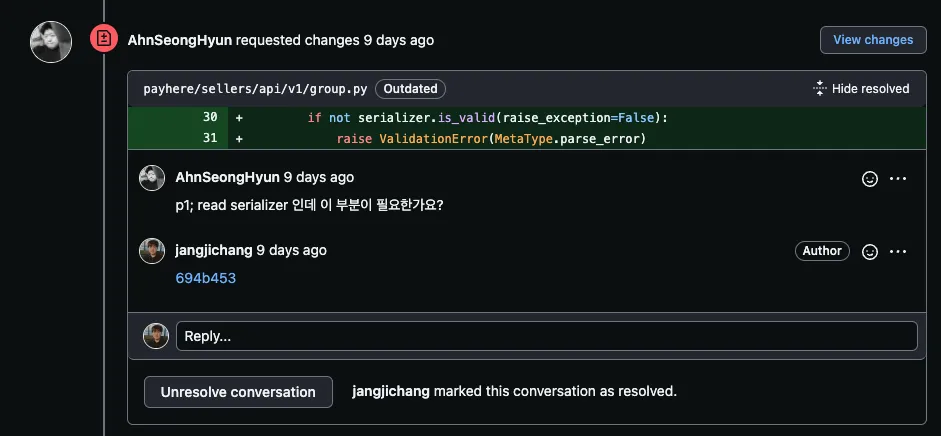
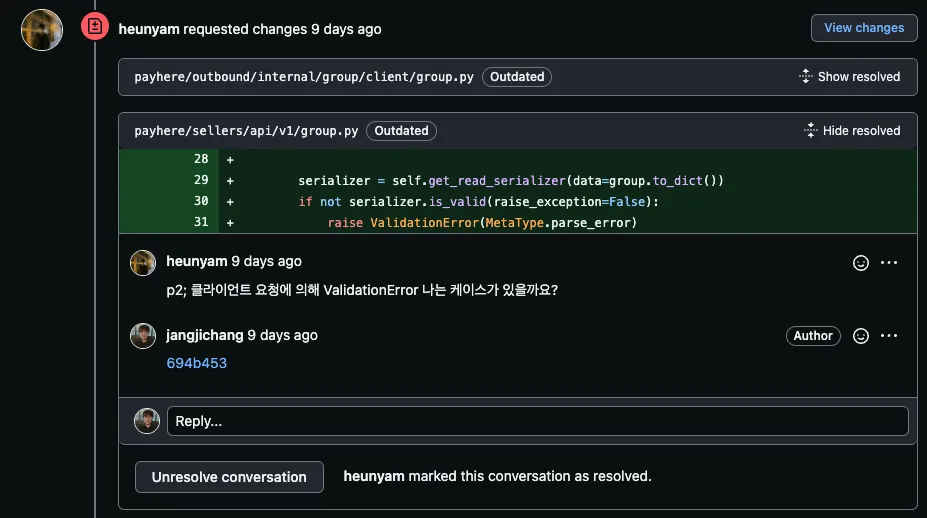
외부 서비스에서 그룹 정보를 조회하고 그것을 serializing하는 것인데, is_valid로 유효성 체크를 할 필요가 있는지에 대한 리뷰였습니다.
생각해보니 유효성 체크를 할 필요는 없습니다. 그래서 아래와 같이 코드를 작성하고 테스트를 실행하니, 에러가 발생했습니다. 😱
class GroupAPIView(GenericAPIView):
serializer_class = GroupReadSerializer
def get(self, request: Request):
...
serializer = self.get_read_serializer(data=group)
return Response(serializer.data
AssertionError: When a serializer is passed a
datakeyword argument you must call.is_valid()before attempting to access the serialized.datarepresentation.
에러를 보니, serializer에 data 키워드 인자를 넘기면, is_valid() 를 호출해야 한다는 내용이었습니다.
이 에러를 해결하는 간단한 방법은 serializer에 data 키워드 인자를 사용하지 않는 것입니다.
class GroupAPIView(GenericAPIView):
serializer_class = GroupReadSerializer
def get(self, request: Request):
...
serializer = self.get_read_serializer(group)
return Response(serializer.data)serializer를 올바르게 사용하는 간단한 방법
serializer에 data 키워드 인자를 넘기면 data 를 사용하기 전에 반드시 is_valid() 를 호출해야합니다.
🚀 내부 동작 조금 더 파보기
에러 메시지를 보고 data 키워드 인자를 필요한 경우에만 넘기고, 그랬다면 is_valid()를 호출해야 한다는 것을 알게 되었습니다. 여기서 조금 더 나아가, 내부 코드를 파악하며 Serializer에서 왜 data 를 사용하기 전에 반드시 is_valid() 를 호출해야 하는지, 그것을 어떻게 구현했는지를 보면서 DRF의 serializer는 어떤 원칙을 갖고 설계했는지 알아보겠습니다.
BaseSerializer에 대해 알아봅니다.

CommentSerializer 예시 처럼 serializer.Serializer를 상속해서 만든 CustomSerializer는 결국 BaseSerializer의 동작들을 따르게 됩니다.
class BaseSerializer(Field):
"""
The BaseSerializer class provides a minimal class which may be used
for writing custom serializer implementations.
Note that we strongly restrict the ordering of operations/properties
that may be used on the serializer in order to enforce correct usage.
BaseSerializer 클래스는 커스텀시리얼라이저 구현 작성에 사용할 수 있는 최소한의 클래스를 제공합니다.
올바른 사용을 강제하기 위해 시리얼라이저에서 사용할 수 있는 operations/properties의 순서를 엄격하게 제한하고 있습니다.
In particular, if a `data=` argument is passed then:
.is_valid() - Available.
.initial_data - Available.
.validated_data - Only available after calling `is_valid()`
.errors - Only available after calling `is_valid()`
.data - Only available after calling `is_valid()`
If a `data=` argument is not passed then:
.is_valid() - Not available.
.initial_data - Not available.
.validated_data - Not available.
.errors - Not available.
.data - Available.˙
"""
BaseSerializer 클래스는 커스텀시리얼라이저 구현 작성에 사용할 수 있는 최소한의 클래스를 제공합니다.
올바른 사용을 강제하기 위해 시리얼라이저에서 사용할 수 있는 operations/properties의 순서를 엄격하게 제한하고 있습니다.
BaseSerializer doc string을 보면 위와 같은 설명이 있습니다. 특히, data 키워드 인자 유무에 따라 operations/properties 사용의 엄격한 규칙을 갖고 있습니다. 아래는 그것을 표로 정리한 것입니다.

이제 serializer가 operations/properties의 순서를 엄격하게 제한하고 있는 걸 알게 되었습니다. BaseSerializer 내부 동작을 보면서 어떻게 제한하고 있는지 코드 진행에 따라 확인해보겠습니다.
serializer = CommentSerializer(data=comment)초기화
class BaseSerializer(Field):
def __init__(self, instance=None, data=empty, **kwargs):
self.instance = instance
if data is not empty:
self.initial_data = data
self.partial = kwargs.pop('partial', False)
self._context = kwargs.pop('context', {})
kwargs.pop('many', None)
super().__init__(**kwargs)data 키워드 인자를 보내고 초기화가 끝나면, 5번째 줄에 의해 인스턴스 변수에 다음과 같은 값이 들어있습니다.

serializer.data
property란? 속성값을 가져오거나, 삭제하거나, 설정할 때 쓰입니다.
@property
def data(self):
if hasattr(self, 'initial_data') and not hasattr(self, '_validated_data'):
msg = (
'When a serializer is passed a `data` keyword argument you '
'must call `.is_valid()` before attempting to access the '
'serialized `.data` representation.\n'
'You should either call `.is_valid()` first, '
'or access `.initial_data` instead.'
)
raise AssertionError(msg)
if not hasattr(self, '_data'):
if self.instance is not None and not getattr(self, '_errors', None):
self._data = self.to_representation(self.instance)
elif hasattr(self, '_validated_data') and not getattr(self, '_errors', None):
self._data = self.to_representation(self.validated_data)
else:
self._data = self.get_initial()
return self._data4번째 줄의 에러 메시지가 눈에 들어오지 않나요? 맞습니다. 저 에러 메시지는 처음에 봤던 그 에러 메시지가 맞습니다. 초기화를 마친 serializer에는 _validated_data 변수가 없습니다. 따라서 3번째 줄의 if 조건문을 통과하고 에러가 발생합니다. serializer에서 data 키워드 인자를 넘겼는데 is_valid() 를 호출하지 않으면 이렇게 동작의 순서를 제한하고 있습니다.
그럼 DRF serializer가 설계한 대로 is_valid() 를 호출하고 data property에 접근하면 어떻게 동작하는지 살펴봅시다. 3번째 줄을 보고 추측하건대, is_valid() 를 호출하면 _validated_data 에 값을 할당할 것처럼 보이는데요. 정말 그런지 확인해보겠습니다.
serializer.is_valid()
def is_valid(self, raise_exception=False):
assert hasattr(self, 'initial_data'), (
'Cannot call `.is_valid()` as no `data=` keyword argument was '
'passed when instantiating the serializer instance.'
)
if not hasattr(self, '_validated_data'):
try:
self._validated_data = self.run_validation(self.initial_data)
except ValidationError as exc:
self._validated_data = {}
self._errors = exc.detail
else:
self._errors = {}
if self._errors and raise_exception:
raise ValidationError(self.errors)
return not bool(self._errors)
data 키워드 인자를 넘겨서 initial_data 변수가 data 값을 갖고 있습니다. 따라서 2번째 줄 assert를 통과합니다. 현재 _validated_data 가 없기 때문에 8번째 줄 이하를 진행하며 _validated_data 와 _errors 값이 할당됩니다.

data property
@property
def data(self):
if hasattr(self, 'initial_data') and not hasattr(self, '_validated_data'):
msg = (
'When a serializer is passed a `data` keyword argument you '
'must call `.is_valid()` before attempting to access the '
'serialized `.data` representation.\n'
'You should either call `.is_valid()` first, '
'or access `.initial_data` instead.'
)
raise AssertionError(msg)
if not hasattr(self, '_data'):
if self.instance is not None and not getattr(self, '_errors', None):
self._data = self.to_representation(self.instance)
elif hasattr(self, '_validated_data') and not getattr(self, '_errors', None):
self._data = self.to_representation(self.validated_data)
else:
self._data = self.get_initial()
return self._data
data 키워드 인자를 넘겨서 초기화했고, is_valid() 를 호출했기 때문에 _validated_data 에 값이 할당되었습니다. 이제 3번째 줄의 조건을 만족하지 않기 때문에 AssertionError가 발생하지 않습니다.
13번째 줄로 가서, 테이블에 보이는 것처럼 _data 변수가 없기 때문에 14번째 줄 이하를 실행합니다. instance를 넘겨줬다면, 첫 번째 조건문처럼 instance를 serialize하고, 아니라면 elif 조건문처럼 validated_data를 serialize합니다.

validated_data property
@property
def validated_data(self):
if not hasattr(self, '_validated_data'):
msg = 'You must call `.is_valid()` before accessing `.validated_data`.'
raise AssertionError(msg)
return self._validated_data
data를 만들 때 필요한 validated_data 는 property로 선언되어 있습니다. 이것도 마찬가지로 is_valid() 를 호출하지 않으면 에러가 발생하는걸 확인할 수 있습니다.
🪢 정리
serializer는 올바른 사용을 강제하기 위해 operations/property의 순서를 엄격하게 제한하고 있습니다. 그 예로 data 키워드 인자 유무에 따라 아래와 같이 따라야 하는 순서가 있습니다.
그럼, data 키워드 인자를 사용하면 serializer 내부에서 동작하는 순서에 따라 할당되는 인스턴스 변수들을 함께 보며 이 글을 마무리하겠습니다.
1. serializer 초기화
2. is_valid() 호출
3. data property
글을 마치며 ☕️
지금까지 DRF serializer의 내부 동작에 대해 알아보았습니다. 글 하나로 serializer의 모든 실행 방식을 파악하기는 어렵지만, serializer가 어떻게 property/operation의 순서를 제한하고 있는지 이해하는 데 도움이 되기를 바랍니다.
백엔드 팀은 코드 리뷰를 사랑하고, 지식의 가치가 보유하는 데 있는 것이 아니라 공유하는 데 있다고 믿는 동료들과 함께하고 있습니다. 백엔드 팀의 문화에 함께 공감하며 성장할 수 있는 동료를 기다리고 있으니, 관심이 있으신 분들은 언제든지 문을 두드려 주세요.
다음에도 유용한 주제로 찾아뵙겠습니다. 긴 글 읽어주셔서 감사합니다.


