정신 차려보니 구글 해커톤 1등이 되어있었다. - Part 1
데이터 엔지니어의 좌충우돌 구글 해커톤 도전기
안녕하세요! 페이히어 데이터 엔지니어 구이헌입니다.
데이터 엔지니어는 보이지 않는 곳에서 항상 데이터를 관리할 뿐만 아니라 지표를 생성하기도 하고, 더 나은 서비스를 위해 개발자, PO 등 다양한 구성원들과 함께 논의하기도 합니다.
구글 클라우드 서비스에 대해서 들어보셨나요? 세계 3대 클라우드 플랫폼으로 잘 알려진 구글 클라우드는 제가 말하지 않아도 모두 알고 계시고, 사용하고 계신 분들도 많을 것이라 생각합니다.
그중 구글 클라우드에서 자랑하는 빅쿼리(BigQuery)는 클라우드 기반 데이터 웨어하우징 서비스입니다. 대규모 데이터를 쉽고 빠르게 저장하고 분석할 수 있으며, 현재 페이히어에서 사용 중인 서비스이기도 합니다. 👍🏻
빅쿼리는 분산 컴퓨팅 아키텍처를 기반으로 하며, 데이터를 수집하고 저장하는 과정에서 발생하는 복잡한 작업을 최적화하여 데이터 분석의 성능을 향상시킵니다. 또한 빅쿼리는 SQL 기반의 질의 언어를 지원, 높은 확장성과 경제성이 뛰어납니다. 그 뿐만 아니라 AI 기능까지도 제공합니다. 🤖
이번 글에서는 구글 캐글 해커톤 후기와 함께 좋은 성과를 거두게 된 전략 방안에 대해 설명하고자 합니다.
BigQuery ML과 함께 머신러닝 설명을 살짝 곁들인? 아! 재미없을 수도 있으니, 수학적인 건 빼고 설명드릴게요!
그럼 이제 시작하겠습니다.
❗️구글 캐글 해커톤에 도전장을 던지다..!
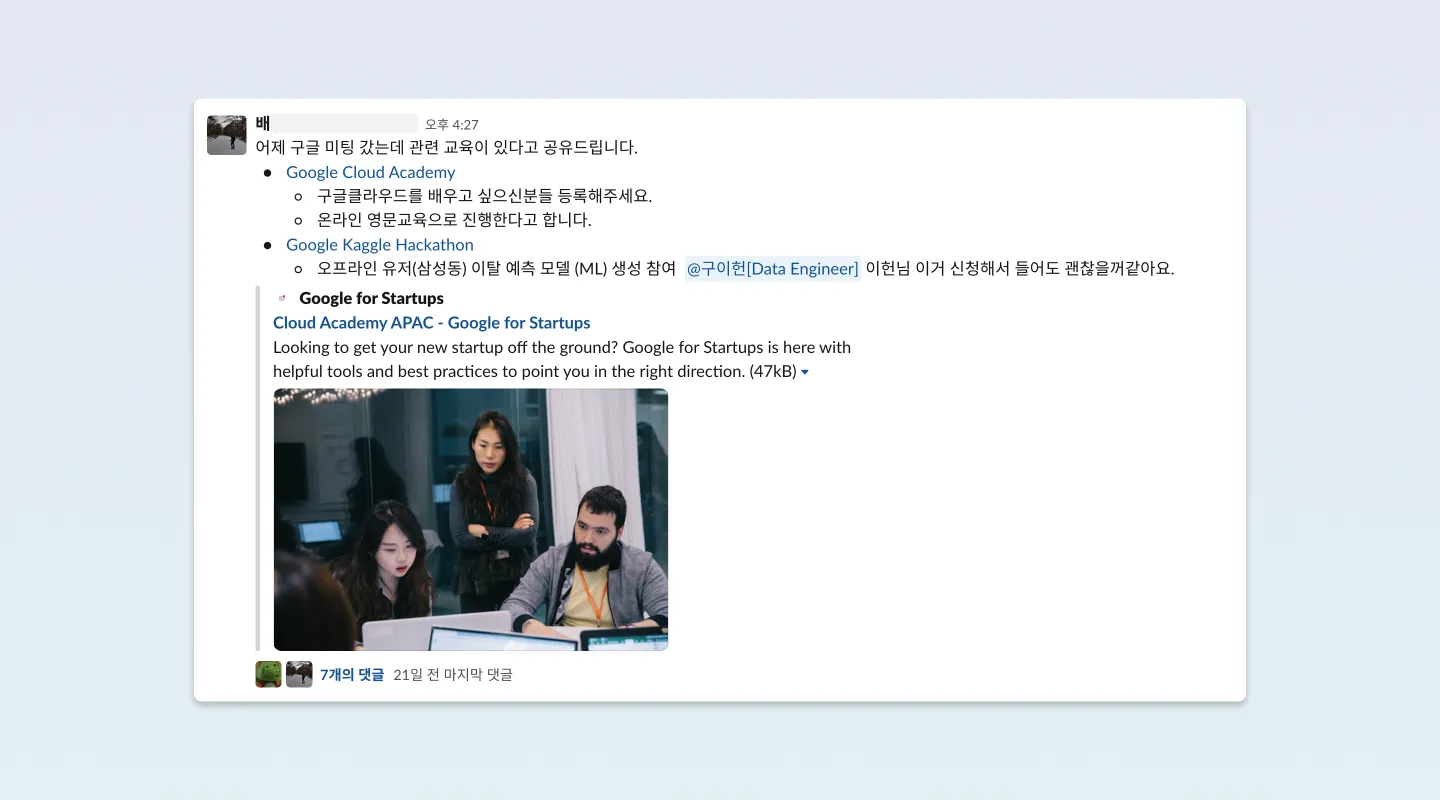
구글 클라우드 미팅을 다녀온 동료분의 권유로 해커톤에 도전을 하게 되었습니다. 구글이라는 회사와 데이터를 사랑하고 관련된 일을 하는 사람이라면, 한 번쯤 도전해 본 ‘캐글’이라는 단어를 본 순간, 이미 제 손은 구글 폼을 통해 지원서 제출 버튼을 눌러버렸습니다. (캐글은 구글에서 2017년 3월에 인수하였습니다!)
페이히어다움, 페이히어의 11가지 핵심 가치 중 하나인 ‘Challenge Beyond Limits’를 실천하기 위해 당당히 해커톤에 도전장을 내밀었습니다.
해커톤 사전 준비
구글 폼을 제출한 이후 한 통의 메일이 저에게 날아왔습니다. 메일에서 유독 눈길이 가는 그림과 글이 보였습니다. ‘Flood-It!’ 앱의 이미지와 “미리 다운로드하여 사용해 보시는 것을 추천합니다.”

해커톤을 위해 지하철을 타고 삼성역 구글 스타트업 캠퍼스에 가는 길, 퍼즐 게임을 설치하여 여러 번 플레이를 해보았습니다.(생각보다 중독성이 있더라고요..?)
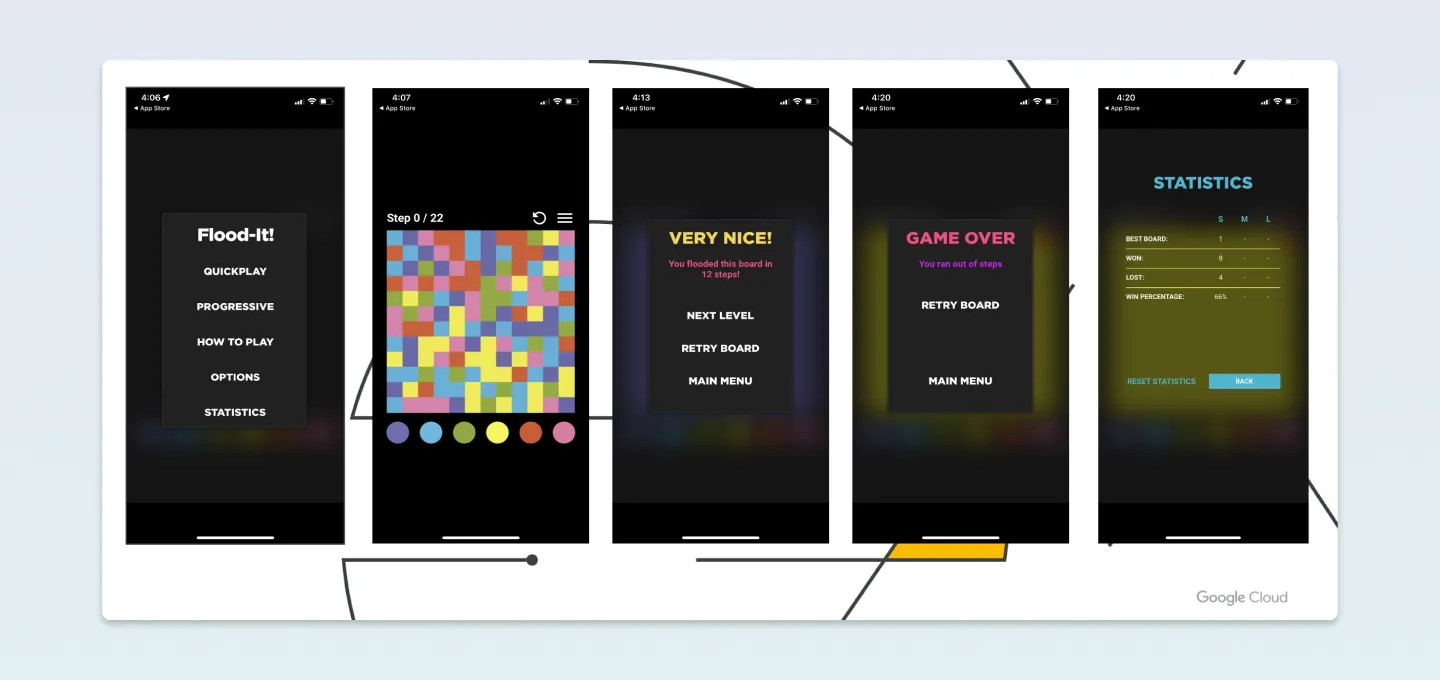
게임을 간략하게 설명하자면, 하단 이미지 속 두 번째 화면을 보시면 왼쪽 상단 끝 점에서부터 시작됩니다. 점으로부터 주변에 있는 색상에 맞춰 아래에 여러 가지 색상의 원을 눌러 진행됩니다. Step(횟수) 내에 모든 영역을 하나의 색으로 통일하는 땅따먹기? 같은 게임이라고 생각하면 될 것 같습니다. 해당 앱의 유저 이탈을 예측하는 문제입니다.
구글 스타트업 캠퍼스의 분위기를 만끽하며,,
여러 회사에서 1명에서 많으면 3명까지 약 30명 정도 되는 사람들이 모여 앉아 정철호 리드님의 위트 있는 발표와 함께 행사는 시작되었습니다. 발표 내용은 고객들의 데이터를 통한 Digital Transformation에 대한 인사이트와 해커톤 진행 시간으로 구성되었어요. (현장 분위기🔥)

앞서 설명드린 내용 중 빅쿼리는 AI 서비스를 제공한다는 내용을 기억하시나요? 즉, 이번 해커톤의 주제는 BigQueryML을 이용하여 유저 이탈 예측을 하는 것입니다.


⚔️ We are not a team. This is a competition.
아! 맞다.. 해커톤은 개인전이었습니다! 전 팀전인 줄 알고 갔었거든요.
1시 40분부터 2시 20분까지 해커톤 과제의 배경과 데이터, 빅쿼리 ML 사용방법, 튜닝 예시 등 다양한 방법을 김태범 리드님께서 알려주셨습니다. 자세한 내용은 이후 제가 해커톤 과제를 어떻게 풀었는지 설명하는 부분에서 이어서 다루겠습니다.
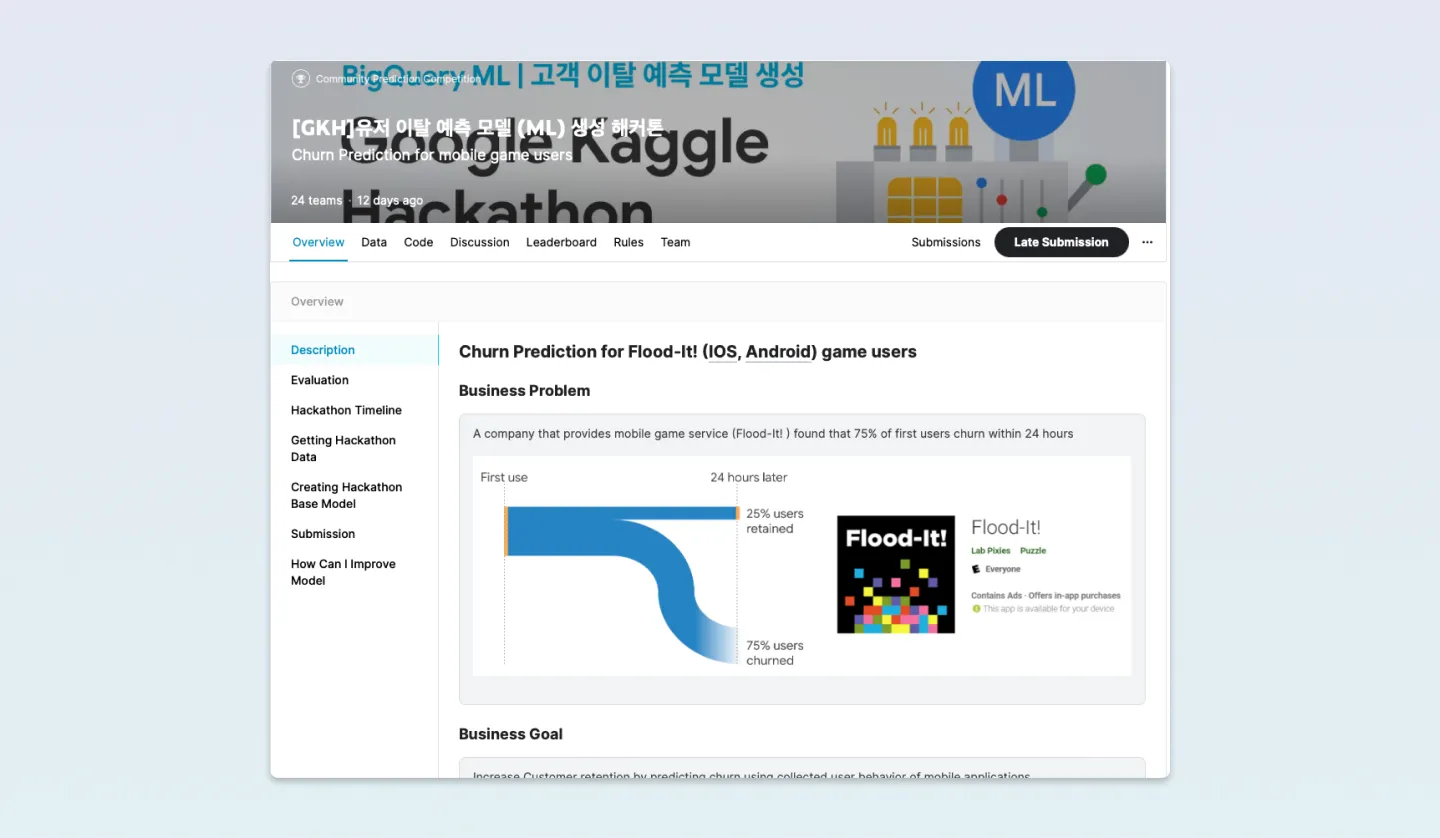
유저 이탈 예측 배경 및 과제는?
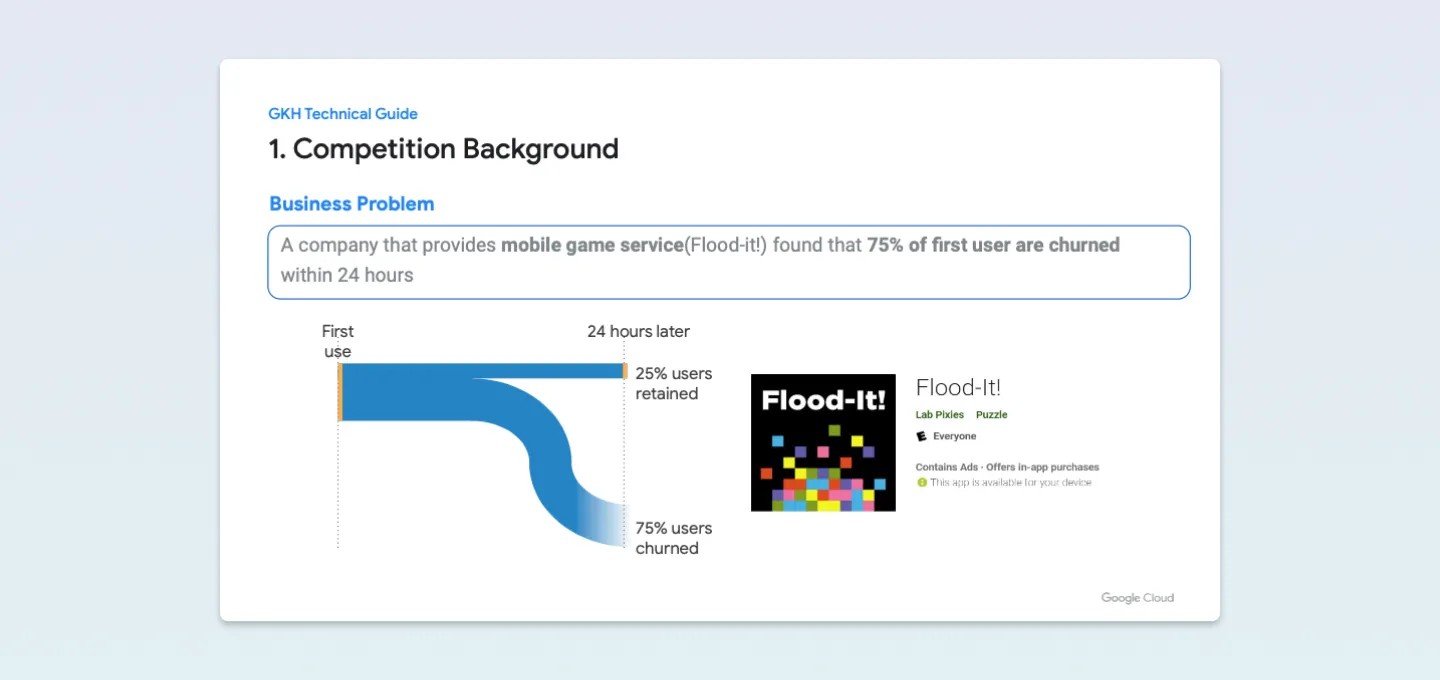
Flood-It! 게임의 유저는 24시간이 지나면 25%는 유지되지만 75%는 이탈하는 것을 볼 수 있습니다.
테스트 데이터 셋에서는 마지막 칼럼인 유저이탈 유무를 나타내는 ‘Churned’이 없네요. 대략 훈련셋 6,200여 개와 과 1,800개가 조금 안되는 테스트 셋을 3 대 1의 비율로 나누어진 것도 확인할 수 있습니다.
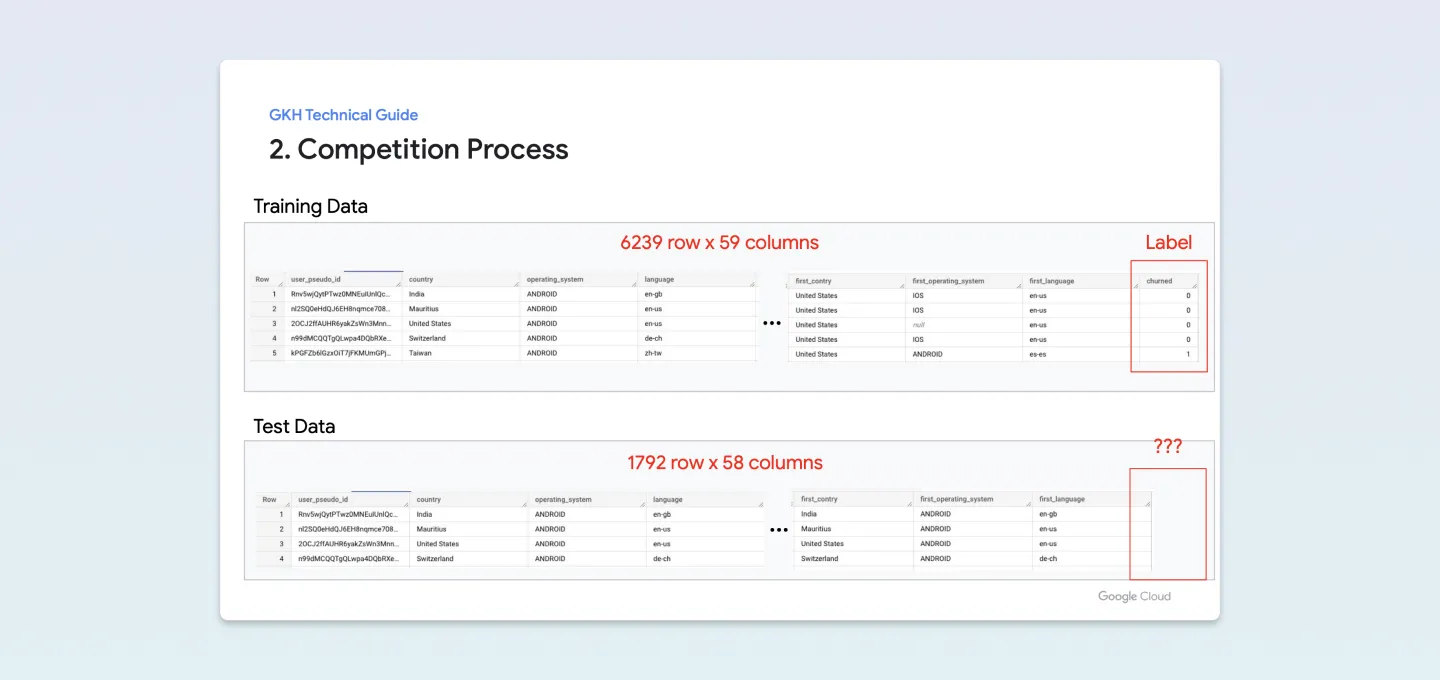
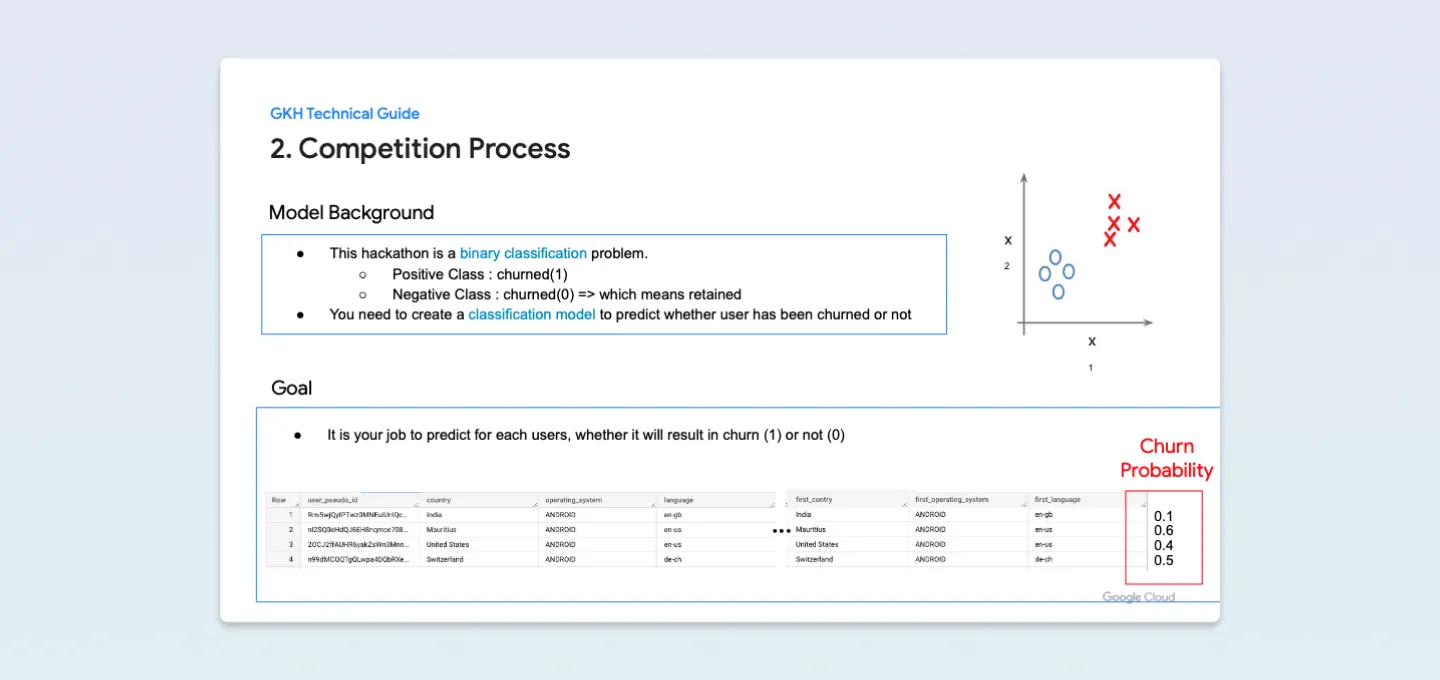
조금 더 살펴보면 이번 해커톤에서
- 이탈 : 1, 이탈하지 않음 : 0
으로 이진 분류 문제를 푸는 것이 목표입니다.
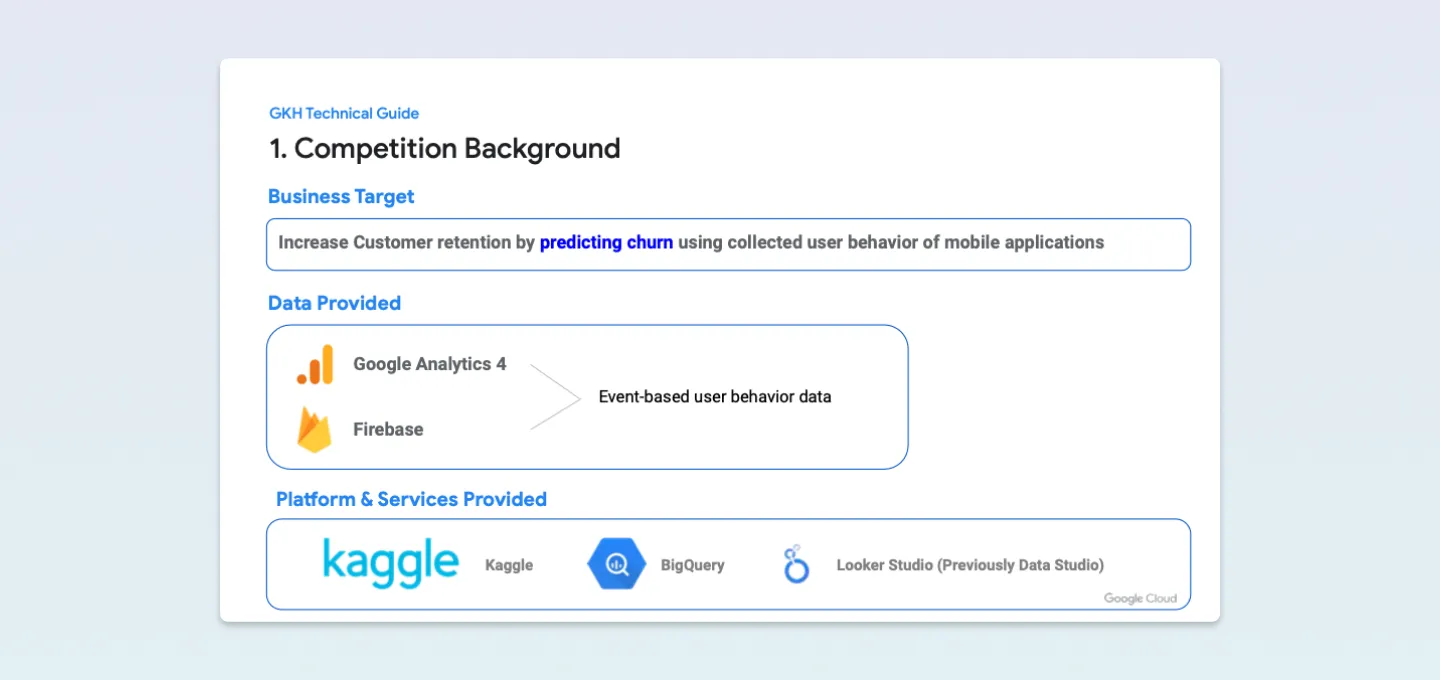
사용하는 플랫폼은 BigQuery, Looker Studio(구. Data Studio), Kaggle입니다.
Business Goal, 우리의 목표!
🛠 Increase Customer retention by predicting churn using collected user behavior of mobile applications
최종적인 목표는 Firebase + Google Analytics4를 통해 수집된 앱의 유저 행동을 이용하여 이탈유저를 예측하고 리텐션을 향상시키는 것!
기 수집된 데이터를 활용하여 EDA 과정 → 모델 생성 → 평가 → 튜닝 → 예측 과정의 전반을 다룹니다.
캐글 [GKH] 유저 이탈 예측 모델 (ML) 생성 해커톤 사이트에서 Data 불러오는 명령어, 베이스라인 코드, 튜닝 예시 등과 같은 이미지를 확인할 수 있었습니다.
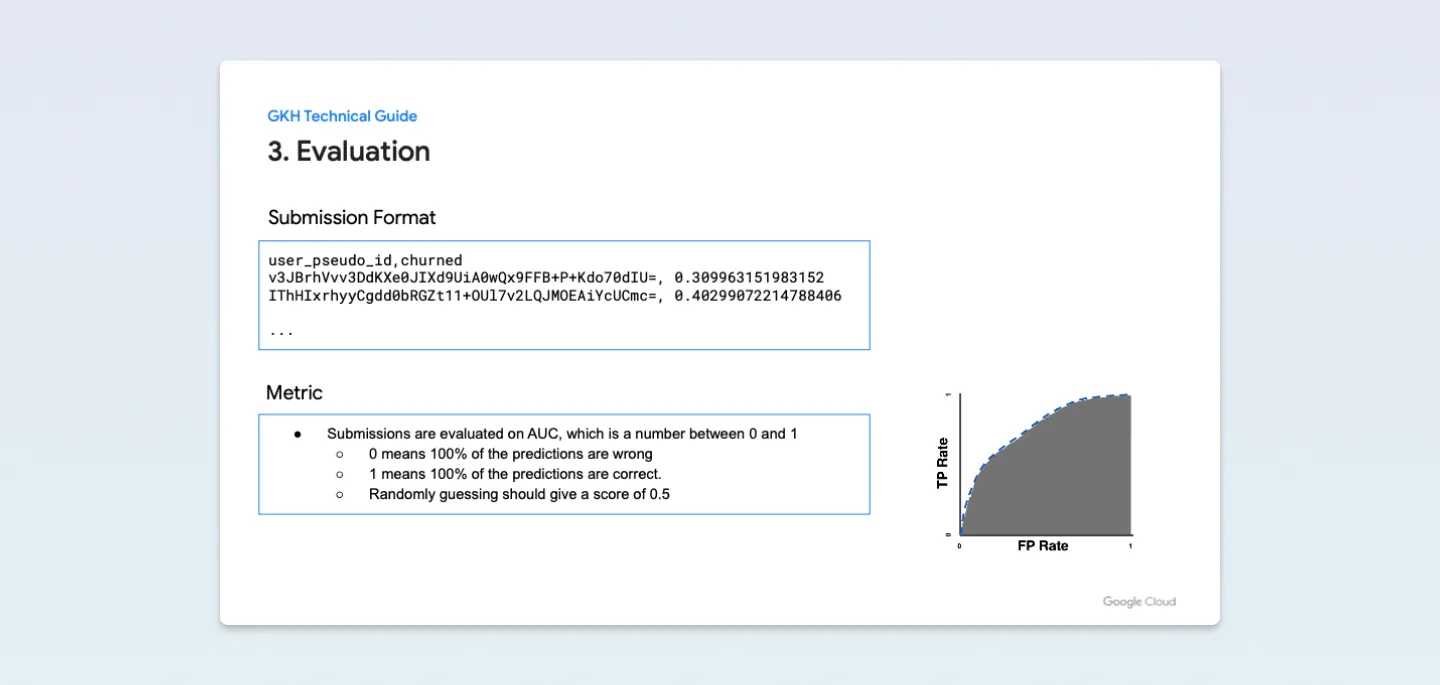

평가 방식은 AUC로, 정답 제출은 5번까지, 마지막으로 제출 포맷은 user_pseudo_id, churned 두 가지를 CSV 형식으로 제출하면됩니다.
신중하게 정답을 제출해야 되며, 문제를 풀기 위한 전체적인 틀을 잡을 필요가 있어 보이네요. (아래 이미지와 같이 캐글 페이지에 자세한 설명과 코드가 포함되어 있었습니다.)
또, AutoML은 점수가 당연히 잘나오니, 이번 해커톤에서는 제외됐습니다.
해커톤 문제를 풀기 전 우리는 3가지를 알 수 있습니다.
1. 2시간 40분 안에 문제를 풀어야 한다.
2. 현재 가지고 있는 데이터는 레코드 수가 6,000여 개로 많지 않지만, 59개의 많은 열을 가지고 있다.
3. 이진 분류 문제이다.
그리고 리드분께서 “데이터는 약간의 정제를 미리 해둔 데이터이다.”라고 귀띔을 해주셨죠.
여기서 어떻게 문제를 풀어야 할지 고민을 많이 했습니다. 이어서 보시죠 🙂
♟️어떤 전략이 유효할까? 근심의 20분.
제목과 같이 근심의 20분은.. 저의 캐글 계정으로 로그인하면 해당 해커톤 주소에서 접근이 안되는 문제가 발생하였습니다. 2시간 40분 중 20분이라는 시간은 로그인을 하는데 소요했었습니다. 시간이 생명인데.. 근심이 가득했죠.🤔
로그인이 완료된 이후 ‘JOIN’ 버튼을 눌러 참여한 이후 전략적인 접근법이 필요할 것 같았습니다.
우선 해커톤 시작 전, 주최 측에서 이미 많은 힌트를 주었습니다.
- 데이터 전처리를 위한 버킷 타이즈 기법
- 모델 선정에는 로지스틱 회귀, 랜덤 포레스트, 부스티드 트리 3가지
- 튜닝 방법에는 스태킹 앙상블 기법
이미 많은 힌트를 얻었기에, 저의 전략은 다음과 같았습니다.
1. 예측을 위한 유효한 값을 선정하고
2. 알맞은 모델을 고른 뒤
3. 튜닝 과정을 거친다. 최대한 빠르게”
유저 이탈에는 어떤 변수가 유효할까? 예측을 위한 유효값을 찾는 여정.
1번 유효한 값을 선정하는 과정부터 보겠습니다.
1번 예측에 유효한 값을 고르기 위해 좋은 방법이 무엇이 있을까요? 저의 경험 상 그리고 보편적으로 사용하는 방법으로는 피어슨 상관계수 분석이 좋겠네요. 정제가 된 데이터라면 충분히 상관 분석만으로도 유의미한 값을 도출할 수 있을 것 같았습니다.
피어슨 상관 계수 분석은 파이썬으로 사용하게 되면, pandas corr()과 같은 명령어로 사용이 가능하고 seaborn과 같은 라이브러리로 아래 사진처럼 예쁘게 만들기도 쉽죠!
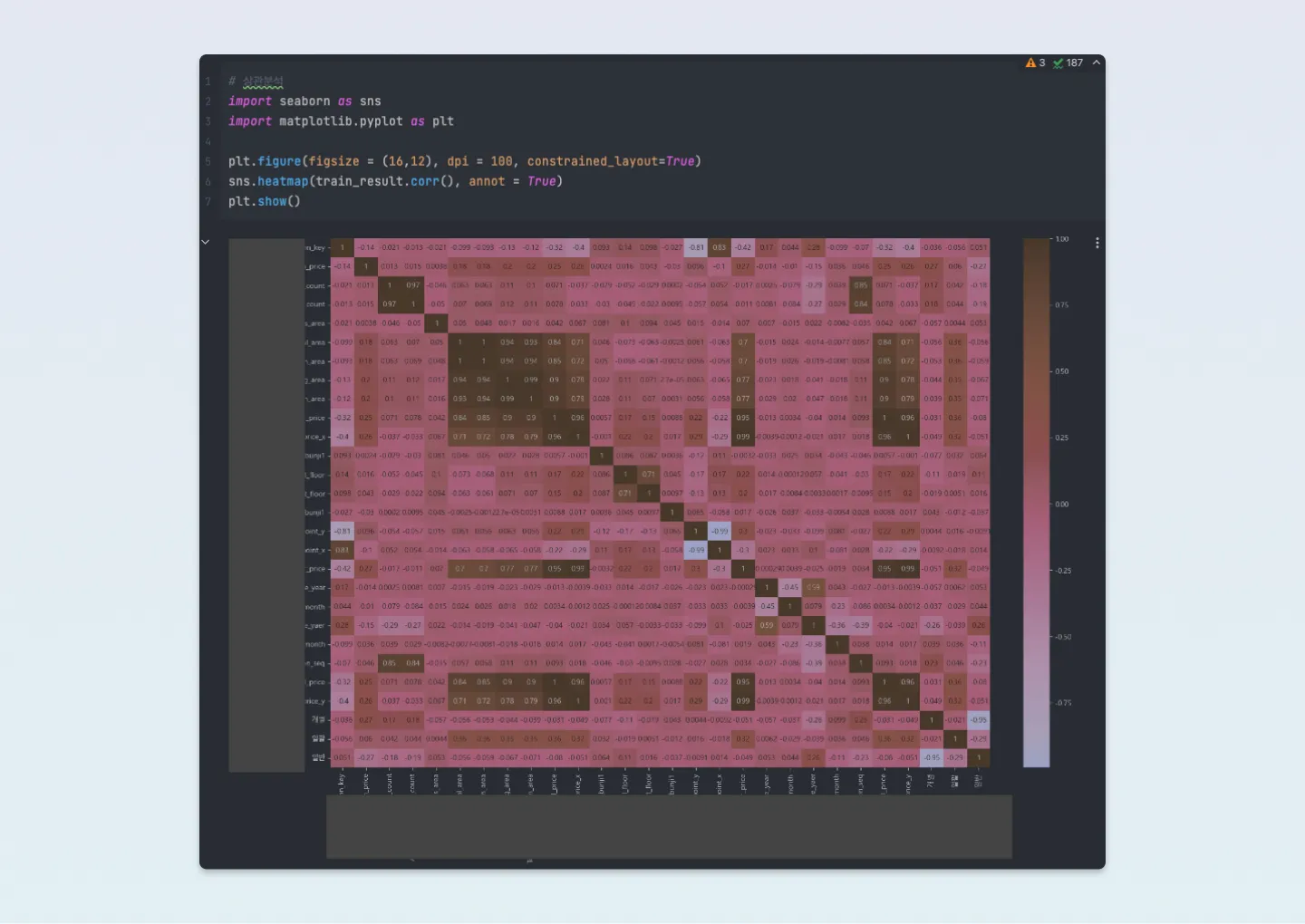
구글 역시 빅쿼리를 통해 피어슨 상관계수 분석 기능을 지원합니다. Looker Studio(구. Data Studio)라는 훌륭한 BI 툴도 있습니다. (아쉽게도 이번 글에서는 상관계수 분석 외에 BI에 대해서 진행하지 않습니다!)
Features = 특성 = 독립변수
그래서 제목처럼 정리해 보자면 훈련을 위한 데이터, ‘독립변수’ 즉, 특성 값을 찾아야되고 영어로 하면 Feature겠죠. 본 글에선 편의상 변수라고 지칭하겠습니다.
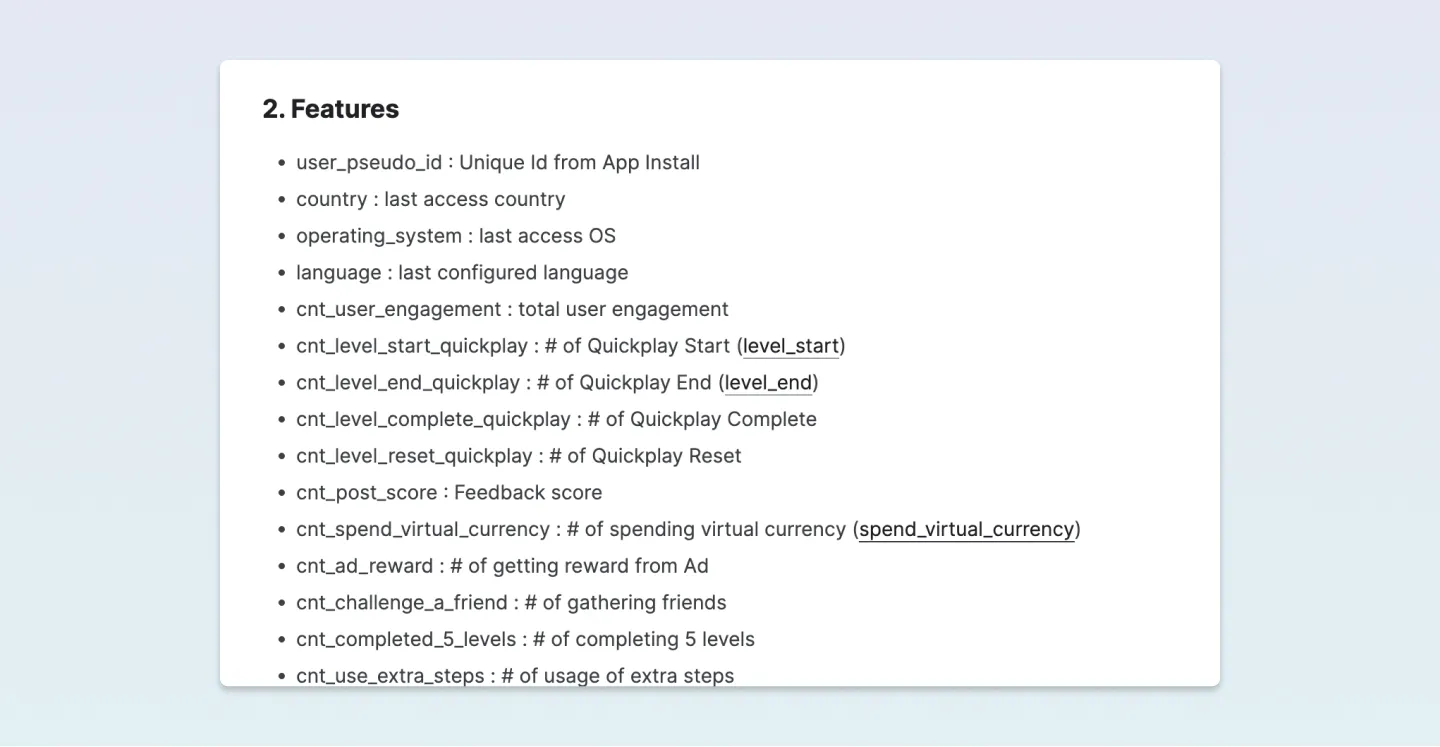
캐글 페이지에서는 변수가 영어로 설명이 되어있습니다.
많은 변수들이 있는데요, 위 이미지와 같이 데이터 셋을 보듯이 58개나 있습니다. 그렇다면 이 데이터에 대한 설명을 봐야겠죠? 여러 가지 데이터에 대한 설명들을 적어 두었네요. 해당 변수들을 가지고 빅쿼리에서 계속 진행해 보겠습니다. 빅쿼리에서 Train 데이터의 필드를 살펴보면서 상관관계 분석을 할 만한 독립변수가 있는지 찾아봤습니다.
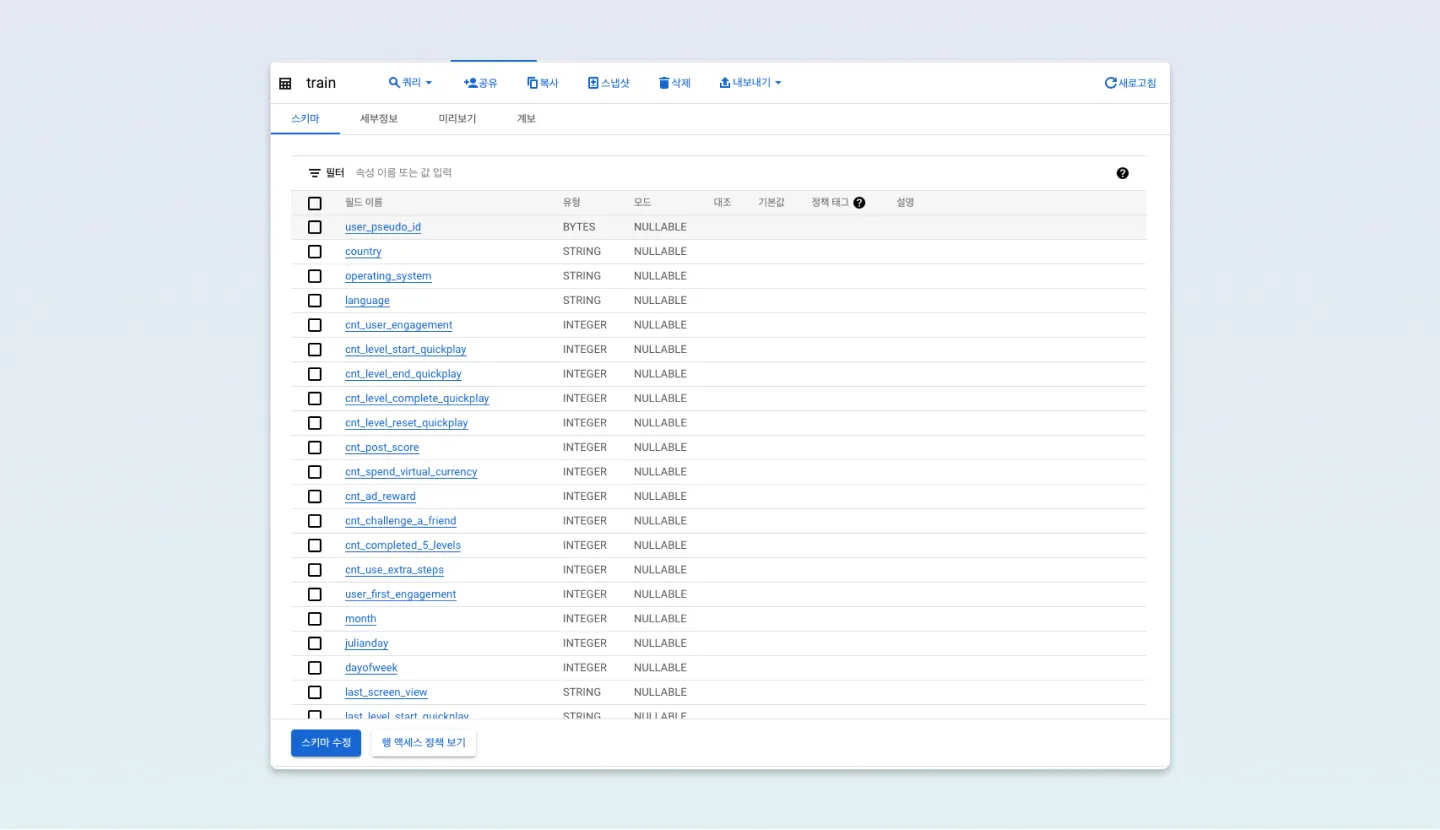
처음 캐글의 변수 설명을 읽다 보니 제 눈에 들어온 변수는 두 가지 였습니다.
- cnt_spend_virtual_currency
- cnt_completed_5_levels
cnt_spend_virtual_currency은 게임을 하면서 가상 통화를 사용한 횟수는 리텐션 지표를 볼 때 유의미하다고 생각했습니다.
또한, cnt_completed_5_levels의 경우 5단계까지 클리어하는 사람이라면 게임을 계속해서 도전할 가능성이 높다고 생각했죠.
과연 5단계까지 클리어 한 횟수(cnt_completed_5_levels)는 이탈 여부 값(churned)에 영향을 많이 줄까요?
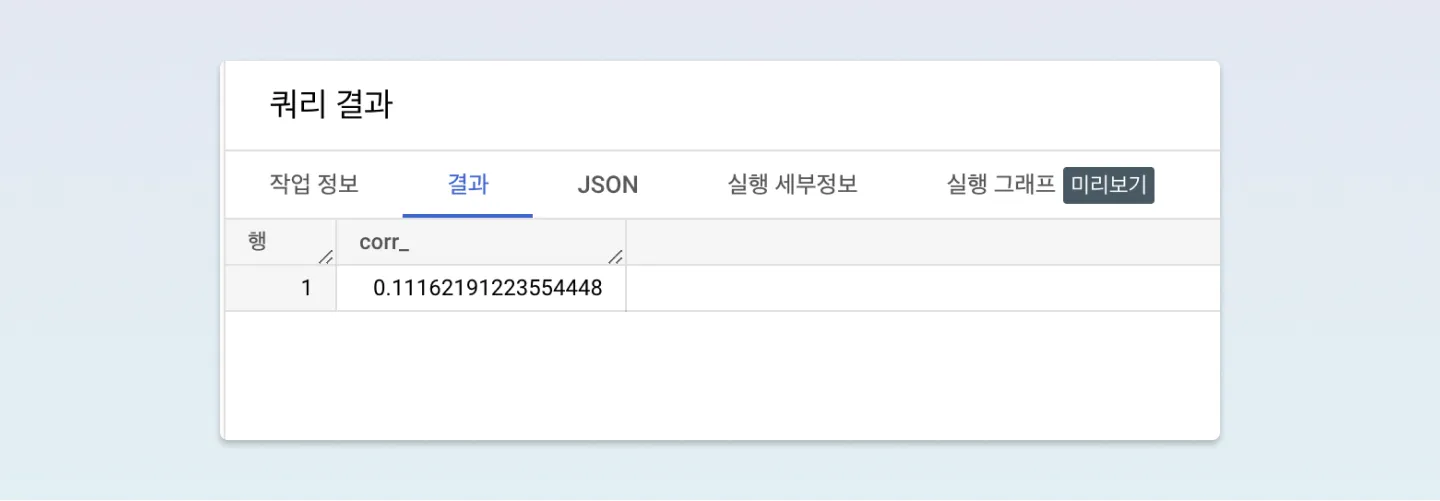
0.1로 시작하네요! 제 생각으론 나름 괜찮은 거 같은데, 간단하게 확인을 하나 더 해보겠습니다.
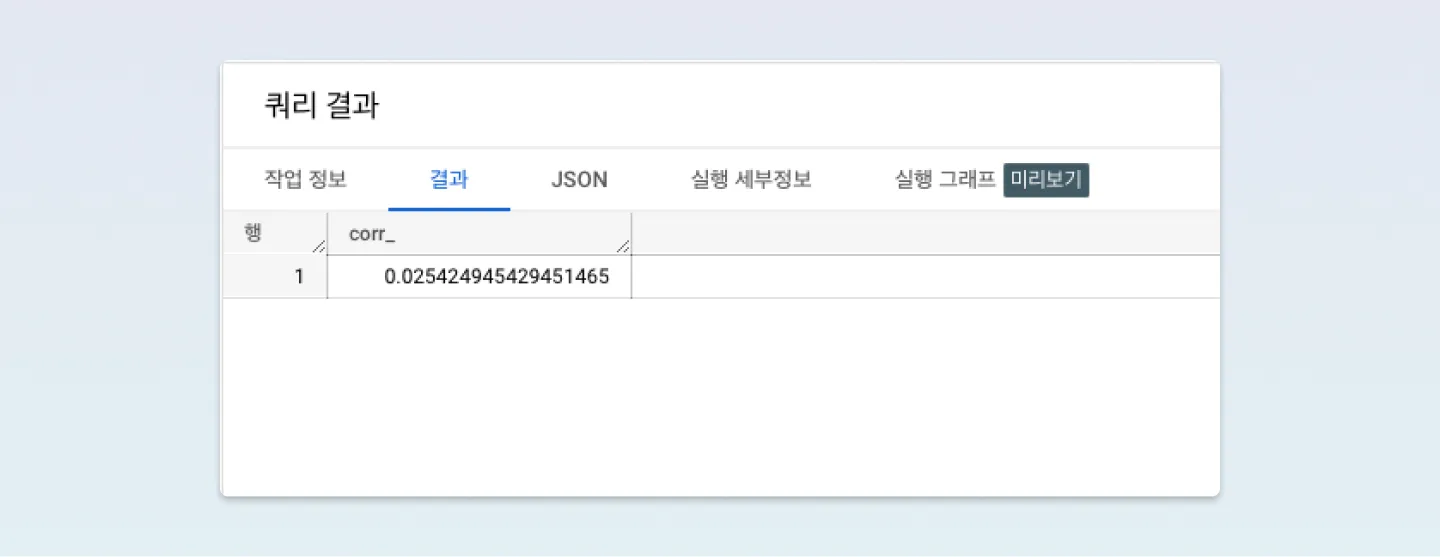
그럼 이것이 유의미한 건지 아무 변수나 뽑아서 상관계수 결과를 확인해 볼까요? cnt_select_content_main_menu메인메뉴 선택 횟수를 선택하였습니다.
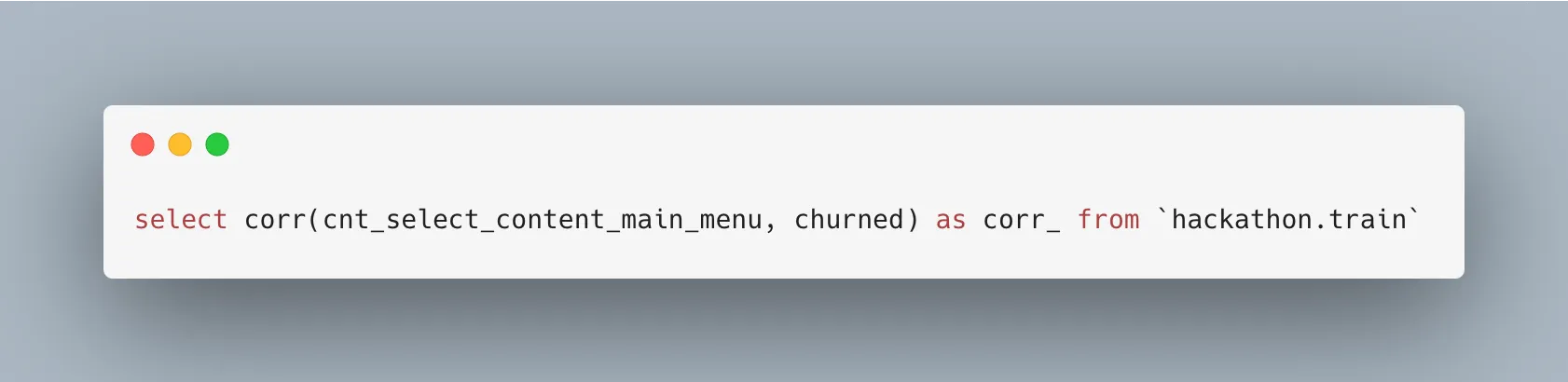
대략 0.02로 나오는군요..! 그렇다면, 제가 생각했던 가설이 잘 맞았다고 생각할 수 있을 거 같습니다.
처음에 제가 선택한 변수 두 가지였던, cnt_spend_virtual_currency와 cnt_completed_5_levels을 선택하여 위와 같이 상관계수를 확인해 보았습니다. 가상 통화를 사용했다면 당연히 유의미하다고 생각했고, 5단계를 성공했다면 게임을 계속해서 할 가능성이 높다고 생각했습니다.
두 가지 변수에 그치지 않고, 추가로 cnt_user_engagement 변수와 같이 사용자 참여가 높고, cnt_post_score 점수 피드백에 대한 반응도 당연히 있을 거라고 생각했죠.
너무 많은 변수들은 모델링에 큰 영향을 주지 못하고 오히려 연산 비용을 높이기에, 이러한 과정들을 반복하여 전 58가지 칼럼 중 7가지 칼럼이 유의미하다고 생각하고 선택을 하였습니다.
하단의 목록은 제가 가져왔던 변수 목록 입니다!
-
cnt_user_engagement : total user engagement
-
cnt_spend_virtual_currency : # of spending virtual currency
-
cnt_post_score_level_1 : # of feedback with scoring 1
-
cnt_post_score_level_5 : # of feedback with scoring 5
-
cnt_completed_5_levels : # of completing 5 levels
-
cnt_post_score : Feedback score
-
user_first_engagement : first touch timestamp
제가 고른 변수들은 상관계수 분석에서 모두 높은 양의 상관관계를 보여줬습니다. 주최 측에서 힌트를 제공한 버킷 타이즈 기법에 대해서 간단하게 설명하고, 모델링 하는 과정으로 넘어가도록 하겠습니다.
빅쿼리에서는 TRANSFORM과 QUANTILE_BUCKETIZE을 이용하여 버킷화(그룹화)를 할 수 있도록 기능을 제공해 줍니다. 간단하게 Transform과 Bucketize 함수를 설명도 드리겠습니다. Bucketize 함수는 BigQuery에서 숫자를 구간으로 나누는 데 사용되며, 이를 통해 데이터를 더 쉽게 분석할 수 있습니다.
예를 들자면, Bucketize 함수를 사용하여 가격 범위에 따라 제품을 그룹화하거나, 연령대에 따라 고객을 분류할 수 있습니다.
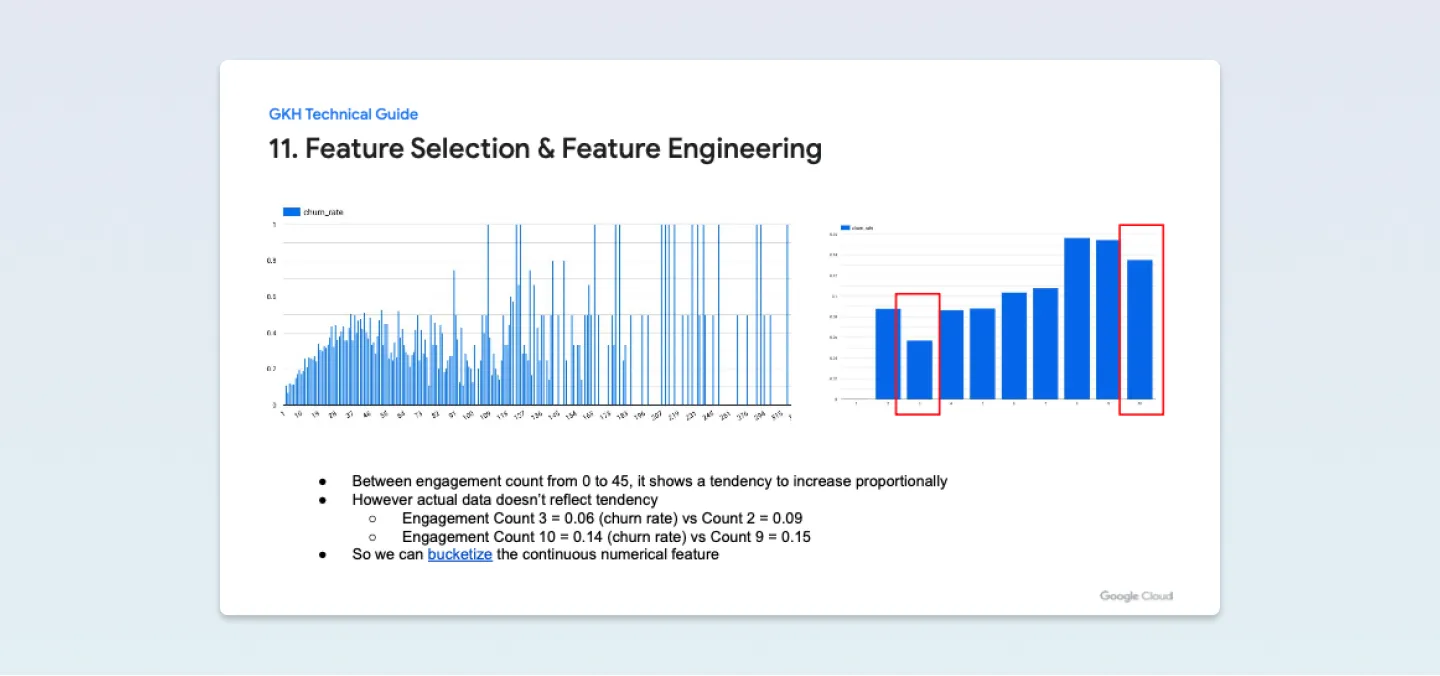
이번 해커톤 과제에서는 cnt_user_engagement(사용자 참여 횟수)의 경우, 참여 횟수가 0에서 45 사이에서 비례적으로 증가하는 경향을 보입니다. 그러나 실제 데이터는 경향을 반영하지 않습니다. 그래서 Bucketize 함수를 통해 경향성을 반영하기 위해 연속적인 숫자의 특성을 버킷화하는 방법을 사용하였습니다.
또한, BigQuery에서 Transform 함수는 데이터를 변환하고 새로운 열을 생성하는 데 사용됩니다. 예를 들어, 일련의 날짜 데이터에서 연도를 추출하거나, 문자열 데이터에서 숫자를 추출할 수 있습니다. Extract 함수나 Bucketize 함수를 사용하게 되면 기존의 데이터를 변형하게 됩니다.
만약 아래의 예시와 같이 변수를 추출하여 사용한다면 모델 평가 단계에서 데이터 포맷을 맞춰주어야 하는 문제가 발생합니다.
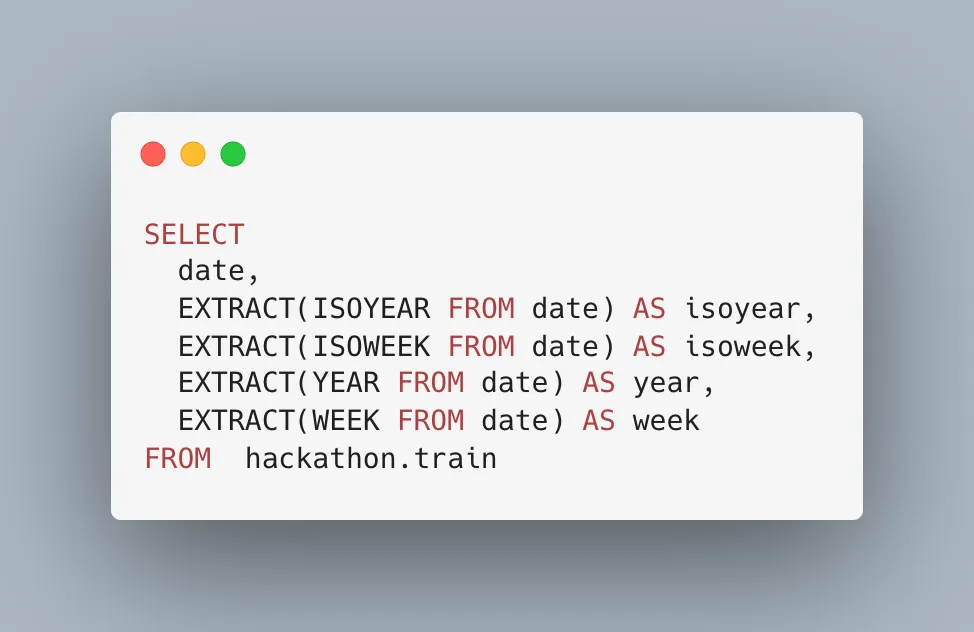
Transform을 통해 이를 방지하고 데이터를 정리 및 필요한 정보를 추출할 수 있습니다.
아래와 같이 사용하면 됩니다. 공식 문서도 같이 첨부할게요!
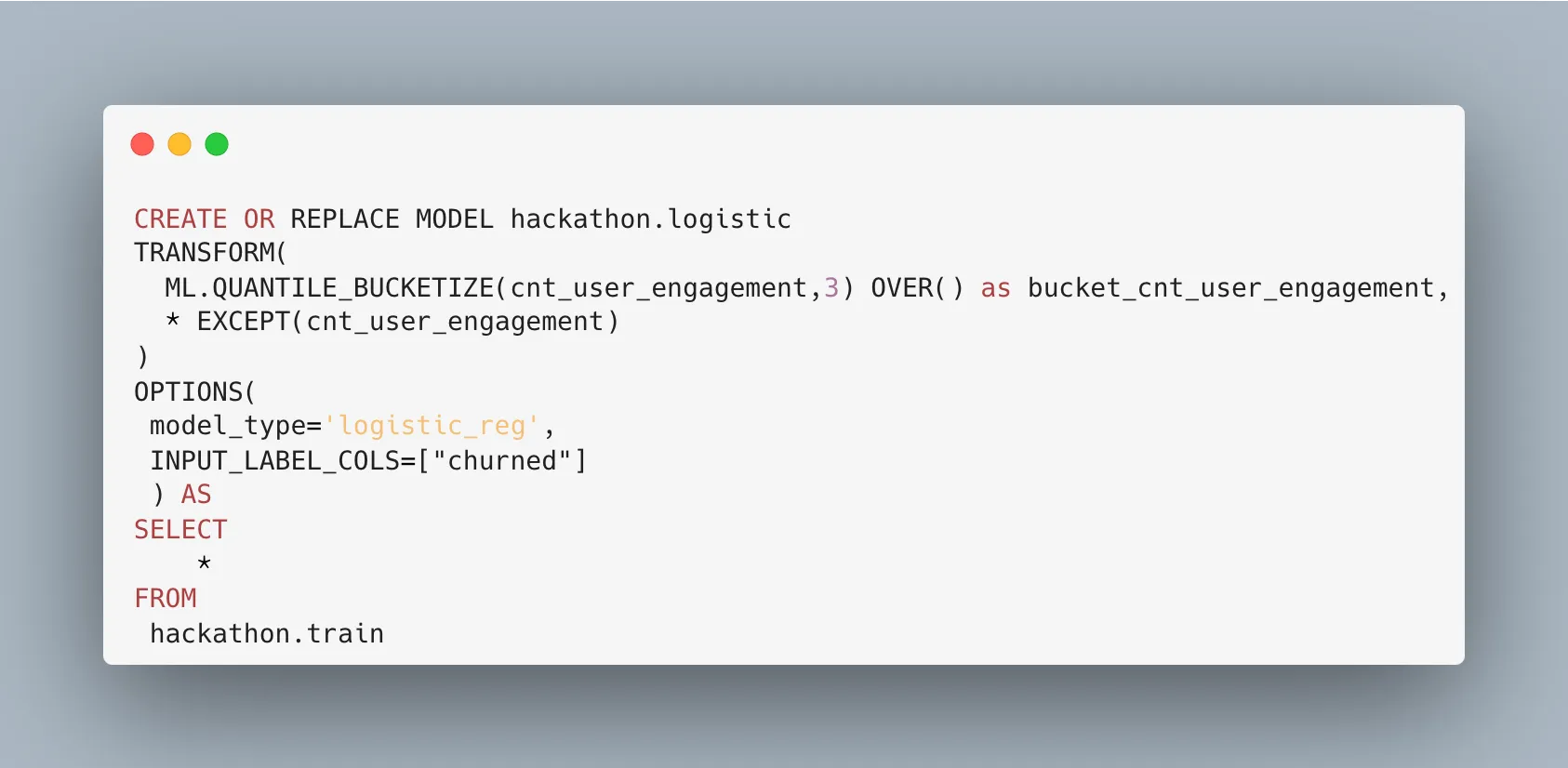
제공된 힌트는 당연히 잘 사용해야겠죠? 👀
처음 제가 말씀드린
1. 예측을 위한 유효한 값을 선정하고,
2. 알맞은 모델을 고른 뒤
3. 튜닝 과정을 거친다.
중에서 1번 유의미한 값을 찾는 여정을 함께 했습니다. 이제 모델링 과정과 파라미터 튜닝 과정이 남았습니다! 어떤 모델을 선택했고, 튜닝은 어떻게 했는지 궁금하시지 않나요?
2부에서 계속됩니다 :)